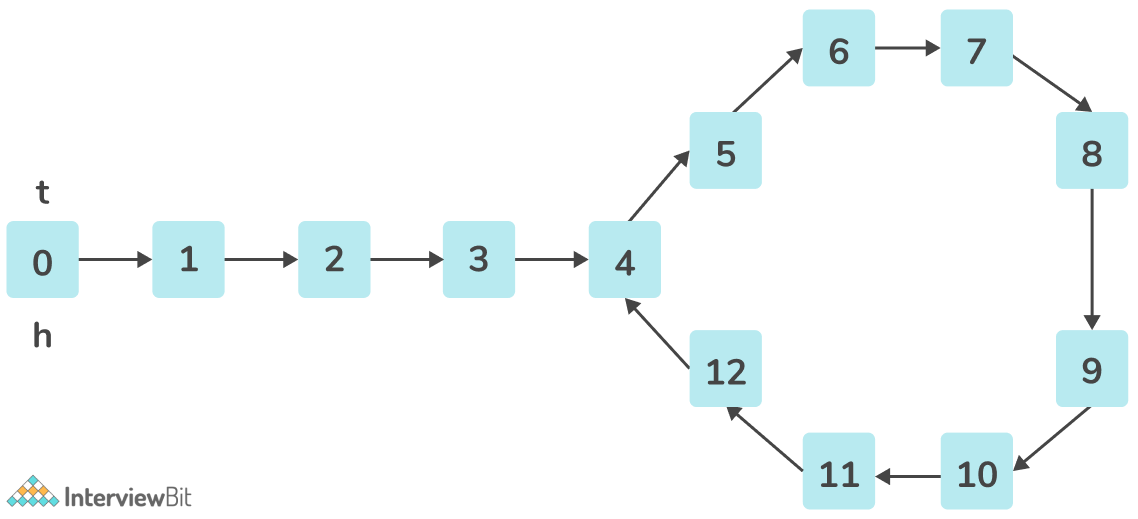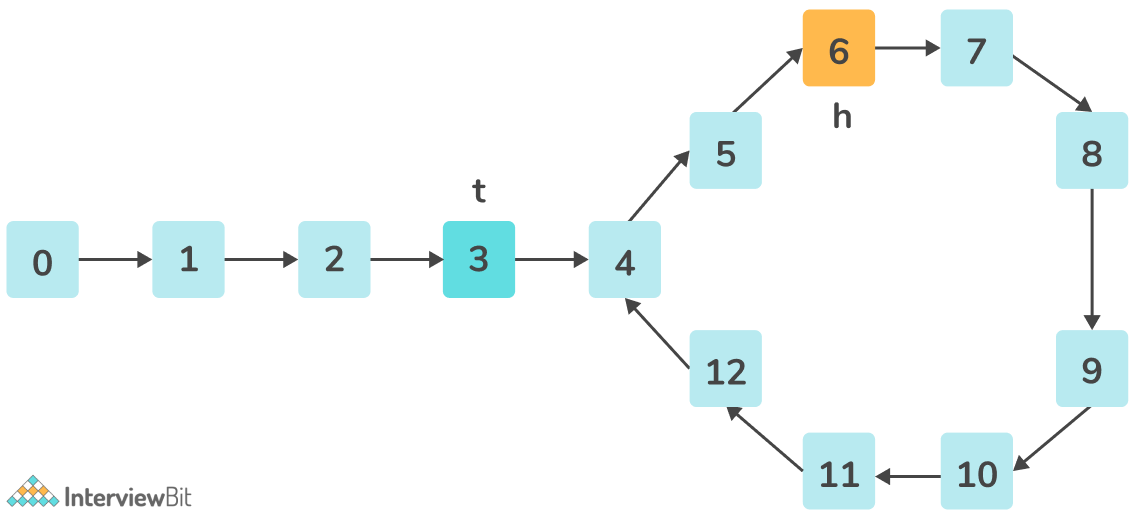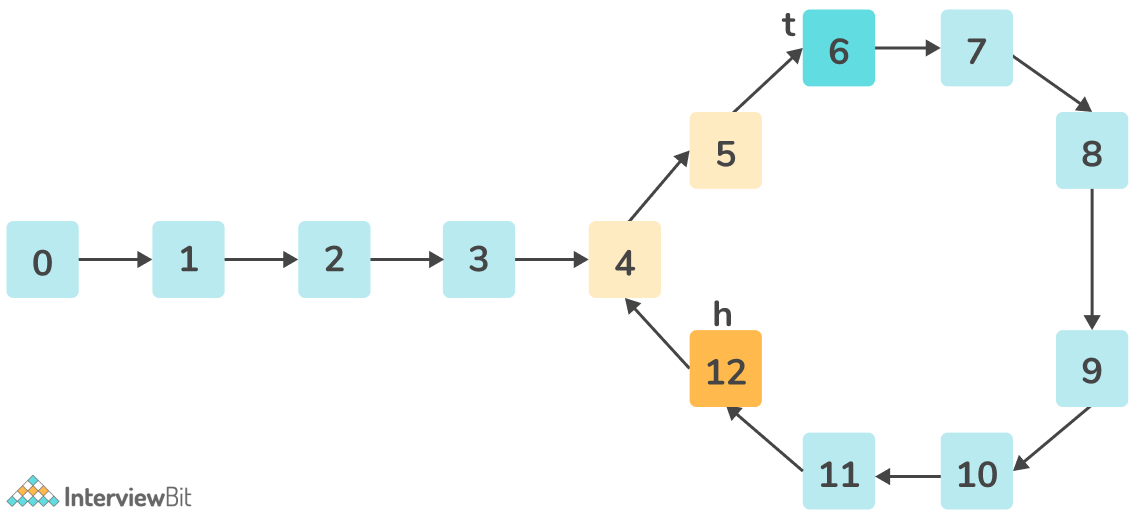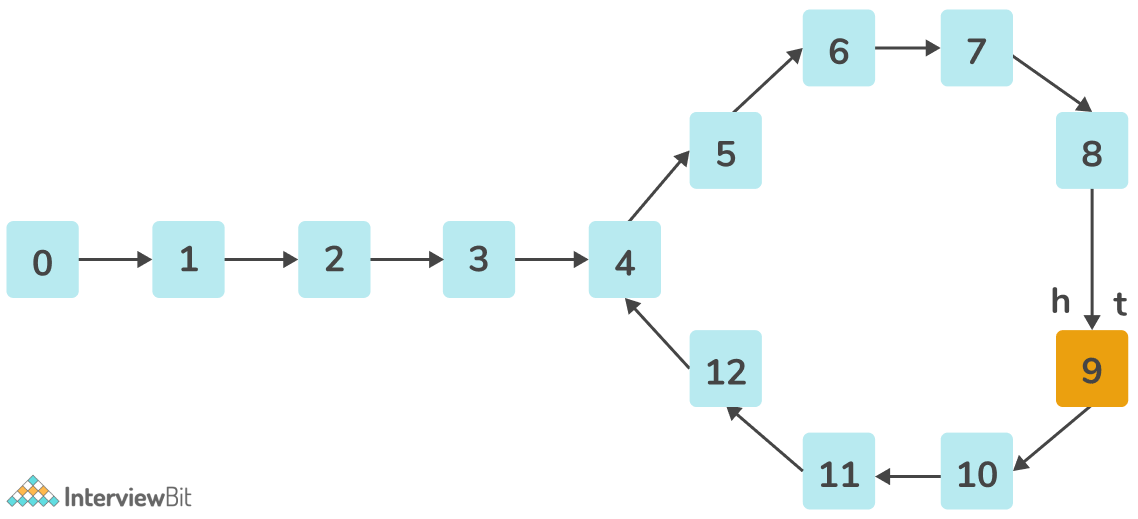
Dijkstra算法实现
Dijkstra算法是一种图遍历算法,用于找到源顶点到图中所有其他顶点的最短路径。 数据结构 顶点(Vertex): 一个保存顶点id的结构体。 边(Edge): 一个保存起点和终点顶点id的结构体,以及边的权重(代价),必须是正整数。 图(Graph): 一个保存所有顶点和边的结构体。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 use std::cmp::Ordering; #[derive(Debug, PartialEq, Eq, Clone, Hash)] pub struct Vertex { // `id`: 顶点的唯一标识符,用字符串表示。 id: String, } #[derive(Debug, PartialEq, Eq, Clone)] pub struct Edge { // `from`: 边的起点顶点id。 from: String, // `to`: 边的终点顶点id。 to: String, // `cost`: 遍历该边的权重或代价。 cost: u32, } #[derive(Debug, PartialEq, Eq)] pub struct Graph { // `vertices`: 一个包含所有顶点的`Vertex`结构体向量。 vertices: Vec<Vertex>, // `edges`: 一个包含所有边的`Edge`结构体向量。 edges: Vec<Edge>, } #[derive(Clone, Eq, PartialEq)] struct Node { // `cost`: 从源顶点到该顶点的当前最短距离。 cost: u32, // `vertex_id`: 该节点所代表顶点的id。 vertex_id: String, } // 为`Node`实现`Ord`特性,使其可用于`BinaryHeap`。 impl Ord for Node { fn cmp(&self, other: &Self) -> Ordering { // 反转`cost`的排序,使`BinaryHeap`表现为最小堆。 // Rust中的`BinaryHeap`默认是最大堆,反转比较结果会使其成为最小堆。 other.cost.cmp(&self.cost) } } // 为`Node`实现`PartialOrd`特性。 impl PartialOrd for Node { fn partial_cmp(&self, other: &Self) -> Option<Ordering> { Some(self.cmp(other)) } } Dijkstra算法 最低代价 将源顶点到自身的距离初始化为0。 将源顶点及代价0推入优先队列。 循环直到优先队列为空。 从优先队列中弹出距离最小的顶点。 如果当前顶点是目标顶点,则跳出循环。 如果已经找到了更短的路径到达当前顶点,则跳过。 遍历所有以当前顶点为起点的边。 计算通过当前顶点到达邻居顶点的代价。 如果找到了更短的路径到达邻居顶点,则更新距离,并将其推入优先队列。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 use std::collections::{BinaryHeap, HashMap}; impl Graph { // 使用Dijkstra算法计算从src到dest的最低代价。 pub fn dijkstra_cost(&self, src: &str, dest: &str) -> Option<u32> { // `distances`: 一个`HashMap`用于存储从源顶点到每个顶点的最短距离。 let mut distances: HashMap<String, u32> = HashMap::new(); // `pq`: 一个`BinaryHeap`(优先队列)用于高效选择距离最小的顶点。 let mut pq: BinaryHeap<Node> = BinaryHeap::new(); // 将源顶点到自身的距离初始化为0。 distances.insert(src.to_string(), 0); // 将源顶点及代价0推入优先队列。 pq.push(Node { cost: 0, vertex_id: src.to_string(), }); // 循环直到优先队列为空。 while let Some(Node { cost, vertex_id }) = pq.pop() { // 如果当前顶点是目标顶点,则返回代价。 if vertex_id == dest { return Some(cost); } // 如果已经找到了更短的路径到达当前顶点,则跳过。 if cost > *distances.get(&vertex_id).unwrap_or(&u32::MAX) { continue; } // 遍历所有以当前顶点为起点的边。 for edge in self.edges.iter().filter(|e| e.from == vertex_id) { // 计算通过当前顶点到达邻居顶点的代价。 let next_cost = cost + edge.cost; // 如果找到了更短的路径到达邻居顶点,则更新距离,并将其推入优先队列。 if next_cost < *distances.get(&edge.to).unwrap_or(&u32::MAX) { distances.insert(edge.to.clone(), next_cost); pq.push(Node { cost: next_cost, vertex_id: edge.to.clone(), }); } } } // 如果没有找到路径,则返回None。 None } } 最短路径 与最低代价的算法大致相同,但需要保存一个previous的HashMap来存储到达每个顶点的最短路径上的前一个顶点。 ...